


Meta (เมต้า) บริษัทแม่เฟซบุ๊กเปิดตัว ”ลาม่า” เวอร์ชันใหม่ “Llama 3.1” เมื่อ 23 ก.ค. 2024 บนคำการันตีตัวโตว่าเป็นโมเดล AI โอเพนซอร์สขนาดใหญ่ที่สุดเท่าที่เคยมีมา จุดเด่นคือพารามิเตอร์ 405,000 ล้านตัว และได้รับการฝึกโดยใช้ GPU Nvidia H100 มากกว่า 16,000 ตัว ทำให้ Llama 3.1 มีประสิทธิภาพเหนือกว่า GPT-4o และ Claude 3.5 Sonnet ในเกณฑ์มาตรฐานหลายรายการ
วันนี้โมเดล Llama 3.1 ถูกเปิดตัวในประเทศไทย พร้อม 8 ภาษาใหม่ที่รวมภาษาไทยด้วยและด้วยฐานะการเป็นโอเพนซอร์สที่ต้องได้รับการอนุมัติจากบริษัทที่มีผู้ใช้หลายร้อยล้านคน พันธมิตรของ Llama 3.1 จึงมีครบทีมบริษัทเทคโนโลยีรายใหญ่ เช่น Microsoft, Amazon, Google และ Nvidia รวมถึงพันธมิตรอีกกว่า 30 ราย ที่จะพร้อมใจช่วยให้นักพัฒนาปรับใช้ Llama 3.1 ได้
สถานการณ์นี้สะท้อนว่าไม่ใช่เรื่องแปลกที่ Mark Zuckerberg ซีอีโอของ Meta จะออกมาคาดการณ์ว่าโมเดล AI โอเพนซอร์สอาจแซงหน้าโมเดลที่เป็นกรรมสิทธิ์ของบริษัทใดบริษัทหนึ่ง เพราะภาวะนี้คล้ายกับปรากฏการณ์ “ลินุกซ์” (Linux) ที่ครองตลาดระบบปฏิบัติการในบางเซกเมนต์ ส่วนหนึ่งเป็นเพราะราคาต้นทุนการใช้งานที่อาจต่ำกว่า ล่าสุดมีการคาดการณ์กันว่า Llama 3.1 จะมีต้นทุนประมาณครึ่งหนึ่งของ GPT-4o ของ OpenAI ในการใช้งานจริง
Llama 3.1 เตรียมสยายปีก

Meta บริษัทแม่เฟซบุ๊กระบุในการประกาศอัปเดท Llama 3.1 ว่าน้องใหม่ตระกูล “ลาม่า” ตัวนี้เป็นระบบปัญญาประดิษฐ์ที่ใช้โมเดลประมวลผลด้วยภาษาขนาดใหญ่ (Large Language Model) แบบโอเพนซอร์สที่ใหญ่และทันสมัยที่สุดในอุตสาหกรรม นอกจากโมเดล 405B ยังมี 70B และ 8B ที่มีการขยายการรองรับความยาวเนื้อหามากถึง 128k

ผลของพารามิเตอร์จำนวนมหาศาลนั้นช่วยให้ Llama 3.1 โต้ตอบได้หลากหลายมากขึ้น สามารถให้เหตุผลได้น่าเชื่อถือยิ่งกว่าเดิม รองรับการสร้างข้อมูลสังเคราะห์และการถ่ายโอนข้อมูลระหว่างโมเดลหรือที่เรียกว่า Model distillation ซึ่งเป็นพัฒนาการที่ทำให้ Llama 3.1ต่างจากรุ่นแรกที่ Meta ได้เปิดตัวไปเมื่อปีที่แล้ว
ในทางเทคนิค โมเดลแบบโอเพนซอร์สของ Llama จะช่วยให้นักพัฒนาสามารถปรับแต่งและฝึกฝนโมเดลของตนเอง รวมถึงรักษาความเป็นส่วนตัวของข้อมูล และช่วยพัฒนาระบบให้แข็งแกร่ง สำหรับ Llama 3.1 405B รวมถึงการอัปเดตโมเดล 8B และ 70B ซึ่งขณะนี้รองรับภาษาไทยแล้ว ถูกเปิดให้นักพัฒนาสามารถเข้าถึงการใช้งานโมเดล Llama ได้ที่ https://llama.meta.com/
สิ่งที่ทีม Meta ทำในขณะนี้คือการเร่งการทำงานขยายฟีเจอร์ให้ Llama 3.1 ใช้ในหลากหลายภูมิภาคของโลก และต่อยอดการดาวน์โหลดรวมที่ Llama ทำได้กว่า 300 ล้านครั้งตั้งแต่เริ่มเปิดตัว สถิติขณะนี้พบว่ามีการพัฒนาโมเดลต่อยอดกว่า 20,000 โมเดลเท่านั้น ซึ่งยังต้องการการอัดฉีดอีกมากจึงจะสมกับคำการันตีว่า Llama เกิดมาสำหรับการใช้งานที่หลากหลาย
นี่อาจเป็นหนึ่งในเหตุผลที่ทำให้ Meta ต้องเทงบจัดการอบรมและทำโครงการต่างๆ เพิ่มเติม โดยล่าสุดได้ให้ทุนสนับสนุนมูลค่ารวม 2 พันล้านดอลลาร์สหรัฐ สำหรับนักพัฒนาและองค์กรทั่วโลก รวมถึงในประเทศไทย โครงการที่น่าจับตาที่สุดคือ Llama 3.1 Impact Grants ซึ่ง Meta จะเตรียมทุนสนับสนุนก้อนใหญ่ให้หน่วยงานที่เสนอโปรเจ็กต์การใช้ Llama AI ในการแก้ไขปัญหาความท้าทายทั่วโลกได้โดนใจที่สุด ผู้ชนะที่ได้รับคัดเลือกจะได้รับเงินทุนสนับสนุนโครงการสูงสุดถึง 500,000 ดอลลาร์สหรัฐ การประกาศผู้ชนะคาดว่าจะมีขึ้นในช่วงต้นปีหน้า 2025
Meta AI แซง ChatGPT

ในขณะที่ Llama 3.1 ถูกผลักและดันอย่างจริงจัง Meta เองก็พัฒนา Meta AI โดยใช้ Llama 3.1 และกำลังเปิดตัวในหลายประเทศและรองรับภาษามากขึ้นในแพลตฟอร์มต่างๆ ของ Meta ทิศทางที่กำลังมาทำให้ Zuckerberg คาดการณ์ว่า Meta AI จะกลายเป็นผู้ช่วย AI ที่ใช้กันอย่างแพร่หลายที่สุดภายในสิ้นปี 2024 แซงหน้า ChatGPT อย่างสบาย ๆ
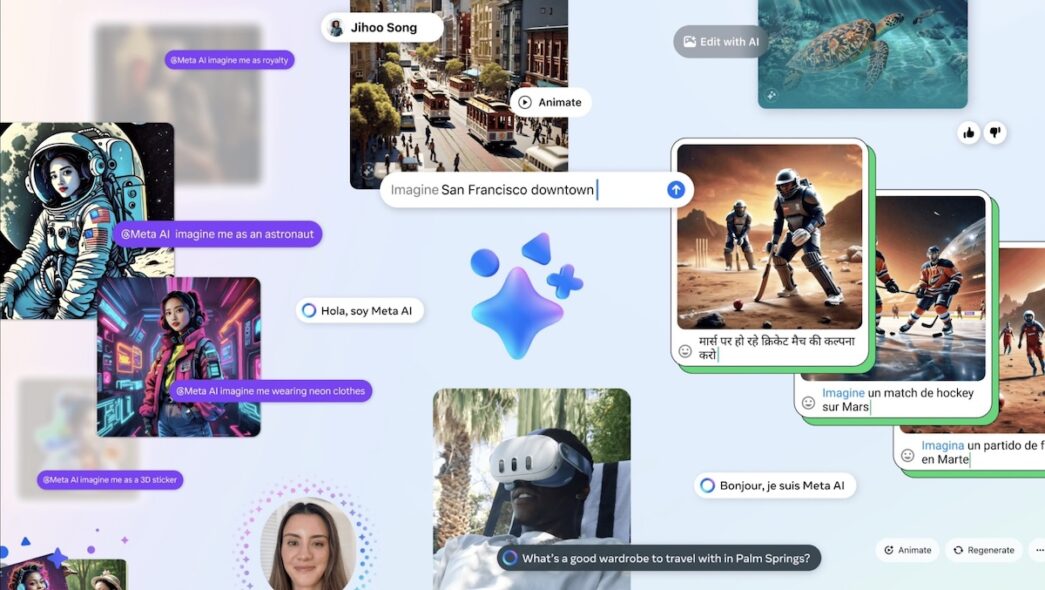
วันนี้ Meta AI ไม่เพียงมีฟีเจอร์เด่นอย่าง “Imagine Yourself” ที่ช่วยให้ผู้ใช้สร้างรูปภาพตัวเองขึ้นใหม่โดยสามารถเพิ่ม ลบ หรือเปลี่ยนองค์ประกอบในรูปได้ตามที่ต้องการ แต่ยังมอบผลลัพธ์หรือคำตอบที่แม่นยำให้ผู้ใช้ที่ถามปัญหาเกี่ยวกับคณิตศาสตร์ หรือการเขียนโค้ดได้ด้วย ปัจจุบัน Meta กำลังนำ Meta AI เข้าไปใช้ในผลิตภัณฑ์และแพลตฟอร์มต่างๆ ของ Meta เช่น WhatsApp, Facebook และอีกมากมาย เบื้องต้น Meta AI ยังไม่เปิดทดสอบให้บุคคลทั่วไปในประเทศไทยได้ลองใช้งาน มีเพียงนักพัฒนาที่สามารถปรับแต่งและฝึกฝนโมเดลของตนเอง ผ่านการเพิ่มภาษาที่ Meta AI จะช่วยให้เข้าถึงผู้ใช้ได้มากขึ้น

ที่สุดแล้ว การเปิดตัว Llama 3.1 ถือเป็นสัญญาณแสดงความก้าวหน้าที่สำคัญในโมเดล AI โอเพนซอร์ส ซึ่งอาจเปลี่ยนสมดุลของอำนาจในอุตสาหกรรม AI ไปสู่ระบบนิเวศที่เปิดกว้างมากขึ้น ดังนั้น คำว่า “ดาวรุ่งสานฝันของ Mark Zuckerberg” จึงเหมาะสมกับ Llama 3.1 และคำพยากรณ์ที่ว่า “AI ของ Meta จะฮอตกว่า ChatGPT” อาจไม่ใช่เรื่องเกินจริงแต่อย่างใด.











